
Dit gastartikel is geschreven door Romano Groenewoud. Het artikel is volledig zijn eigen mening en reflecteert niet noodzakelijkerwijs de mening van Qonvert.
Wat is facetnavigatie?
Vrijwel iedere grote e-commerce website maakt gebruik van facetnavigatie. Facetnavigatie stelt de bezoeker in staat om zich met behulp van zoekfilters een weg te banen door het grote aanbod op de site. Bij een kleine en overzichtelijke website is dit niet nodig, maar voor een site met een groot aanbod en veel verschillende zoekvariabelen is facetnavigatie de enige klantvriendelijke oplossing. Neem bijvoorbeeld Funda, dat meer dan 15 verschillende filters biedt, waardoor een heel specifieke filtering van de zoekresultaten mogelijk wordt:
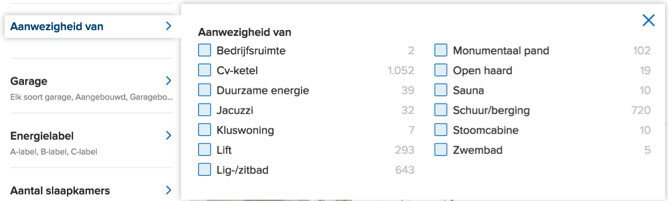
Een van de vele filters op Funda.nl
Zo wordt het zoeken naar een passende woning veel gemakkelijker dan zonder facetnavigatie het geval zou zijn. Een zoekopdracht naar een woning in Amsterdam, met een prijs tussen de 500.000 en 750.000 euro, levert op Funda.nl zo’n 560 resultaten op. Ben je in die prijsklasse op zoek naar een woning met een stoomcabine, dan hoef je die niet allemaal te gaan bekijken, maar slechts een stuk of tien.
De gevaren van facetnavigatie voor SEO
Maar zo fijn als facetnavigatie kan zijn voor de bezoekers van de website, zo gevaarlijk kan het zijn voor de search performance ervan. Een slechte implementatie van facetnavigatie kan leiden tot een enorme massa aan URL’s die allemaal indexeerbaar zijn, terwijl dat niet het geval zou moeten zijn. Het doorzoeken en indexeren van al die pagina’s is tijdsverspilling van de crawler en gaat ten koste van het doorzoeken en indexeren van de belangrijkere pagina’s van de site. Daarbij zorgt het ervoor dat de inhoud van de site volledig versnipperd raakt in de zoekresultaten van Google. Een paar voorbeelden:
Het eerste probleemgeval is de onlinewinkel van AH.nl. Doe je de dagelijkse boodschappen en heb je melk nodig, dan levert een zoekopdracht op de site zelf een dikke 660 resultaten op. Maar dezelfde zoekopdracht op Google vindt maar liefst 44.500 pagina’s:

Heel veel melk
Een andere bekende site met facetnavigatie is Bol.com, toevallig of niet van dezelfde eigenaar als AH.nl. Bol verkoopt boeken, waaronder die van bestsellerschrijver Dan Brown. Brown heeft al aardig wat boeken op zijn naam staan, maar het zijn er geen duizenden. Evenmin zijn er 3500 verschillende versies van het boek ‘de Da Vinci Code’ in omloop. Een zoekopdracht naar “Dan Brown” en “Da Vinci Code” op de site van bol.com levert respectievelijk 417 en 222 resultaten op. Maar met een Google-zoekopdracht vindt je maar liefst 9.190 geïndexeerde pagina’s voor de auteur en 3.580 voor het boek:
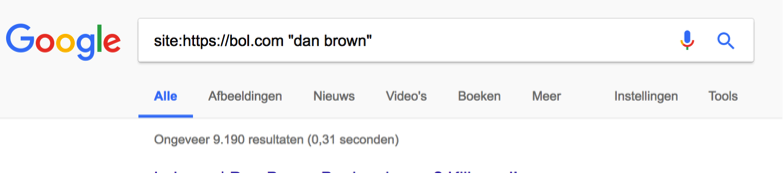
9010 resultaten. Da’s wel heel veel boeken.

3500 resultaten voor de ‘da Vinci Code’. Het is een complot!
Kijken we, via Google, op de site van Libris, dan zie we dat ze het daar beter gedaan hebben. ‘Slechts’ 483 resultaten voor de ‘da Vinci Code’, maar daar zitten ook de resultaten bij van de verschillende vestigingen in het land die samenwerken onder de naam Libris.
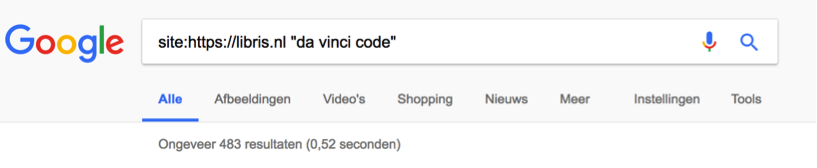
Libris doet het ietwat beter.
Zowel Bol als Albert Heijn kunnen het zich tot op zekere hoogte veroorloven slordig te zijn. Door hun naamsbekendheid en sterke marktpositie zullen veel klanten rechtstreeks naar hun site gaan en daar pas beginnen met winkelen. Desondanks is het opvallend dat twee van de grootste sites van Nederland hier kansen laten liggen. Niet iedereen kan zich die luxe permitteren. Wat voor AH en Bol ‘kruimels’ zijn die ze over het hoofd kunnen zien, is voor de meeste websites van levensbelang.
SEO en facetnavigatie: workarounds en oplossingen
De problemen die facetnavigatie kan opleveren zijn niet eenvoudig te verhelpen, want zelfs de grotere commerciële sites worstelen er nog mee. Toch zijn er een aantal relatief simpele manieren om het probleem te verkleinen. En er is zelfs een volledige oplossing, maar die is complex en tijdrovend en daardoor meestal niet op korte termijn te implementeren. Daarom zal meestal een combinatie van onderstaande methodes nodig zijn:
Noindex en nofollow tags
De snelste en makkelijkste oplossing is het gebruiken van de ‘noindex’ tag. Deze heeft als doel de crawler te laten weten dat het de pagina’s niet hoeft te indexeren, wat een eenvoudige manier is om te voorkomen dat er gedupliceerde content in de zoekresultaten verschijnt. Het gebruik van de noindex-tag voorkomt echter niet dat de crawler de pagina’s bekijkt, wat ten koste gaat van het crawl-budget. Daarnaast houden de ‘noindex-pagina’s’ gewoon hun link equity, die daarmee in feite verloren gaat. Dezelfde nadelen kleven aan het gebruik van de ‘nofollow’ tag bij interne links. Ook deze methode is niet waterdicht. Er bestaat nog steeds een kans dat de pagina’s worden geïndexeerd, bijvoorbeeld doordat andere sites ernaar linken zonder de nofollow tag, of als de URL’s vermeld staan in een sitemap die naar Google is gestuurd. En ook bij deze methode gaat de link equity van de ‘nofollow’-pagina’s in feite verloren.
Canonical tags
Het probleem van de verloren link equity is op te lossen door gebruik te maken van ‘canonical tags’. Een canonical tag deel je uit aan een groep van min of meer dezelfde pagina’s en verwijst deze pagina’s naar één van hen. Zo zouden crawlers op de volgende adressen kunnen stuiten, die allemaal naar dezelfde pagina verwijzen:
- http://www.example.com
- https://www.example.com
- http://example.com
- http://example.com/index.php
- http://example.com/index.php?refer=twitter
Met canonical tags laat je Google weten dat één van al deze URL’s alle autoriteit en link-equity verdient. Zo maak je een einde aan concurrerende duplicaten en wordt de link-equity op een nuttige manier gebundeld (let wel goed op bij het gebruik van canonical tags). Maar nog steeds wordt er crawl-budget verspilt.
Robots.txt en de ‘hatchet-approach’
Om de kans op verkwisting van het crawl-budget te verminderen, kan je door gebruik van parameters en ‘disallow’ in ‘robots.txt’ ervoor zorgen dat delen van de site niet gecrawld worden. Dit gaat wel weer ten koste van de ‘link equity’ van de geblokkeerde pagina’s. Zo zou AH alle URL’s met melk-varianten (/houdbaar, /vers, /liter, /halve liter, /vol, /halfvol, enzovoorts) met een canonical tag kunnen leiden naar de default ‘melk’ pagina. Toch bestaat er nog steeds een kans dat de geblokkeerde pagina’s worden geïndexeerd, ook al worden ze niet meer bezocht door de crawlers. Zodra er ergens op het Internet ook maar één ‘follow link’ verwijst naar een URL met dezelfde parameters (bijvoorbeeld melk/halfvol) kan Google besluiten de pagina (en alle andere pagina’s met dezelfde parameters) alsnog te indexeren.
Een variant op de robots.txt-methode is de zogenaamde hatchet-approach. Daarbij worden de top-level pagina’s gecrawld en geïndexeerd, maar zodra er een facet (filter) wordt gebruikt bij het zoeken wordt de pagina uitgezonderd via robots.txt. De ‘hatchet-approach’ is effectief maar heeft wel iets weg van een botte bijl. Het belangrijkste nadeel van deze methode is dat er geen sterke organische landingspagina’s kunnen ontstaan.
AJAX en JavaScript
Alle oplossingen die tot nu toe de revue zijn gepasseerd zijn onvolledig, al kan een combinatie van methodes voor sommige sites een goede (tijdelijke) oplossing zijn. De enige volledige oplossing, die gedupliceerde content voorkomt, geen crawl-budget verspilt en de link equity niet vermorst, is Javascript in combinatie met XML (AJAX). Het levert een prettige en bruikbare navigatie op voor de gebruiker, laat de URL onveranderd tijdens het zoeken en filteren én het biedt de mogelijkheid om bepaalde facet-combinaties, bijvoorbeeld degenen die het meest worden gebruikt, te indexeren. Het implementeren van een AJAX-oplossing kost natuurlijk meer tijd en geld dan het aanpassen van tags en is daarom vooral aan te raden als de website toch al grondig gerenoveerd gaat worden. Het is buiten de scope van dit artikel om in detail te beschrijven hoe je het beste te werk kan gaan bij het implementeren van AJAX, maar er zijn voldoende bronnen die je op weg kunnen helpen, waaronder die van Google zelf.
Het maken van de juiste keuze
Er is dus een ruim palet aan mogelijkheden om schade aan organische vindbaarheid door het gebruik van facetnavigatie te beperken of zelfs te voorkomen.
Wat de beste oplossing is hangt af van ambitie, budget en specifieke problemen. Wanneer de verspilling van het crawlbudget de grootste kopzorg is, dan is het zinvol om alleen de pagina’s van hoofdcategorie en subcategorie te laten indexeren en de andere pagina’s waarbij een facet wordt gebruikt te voorzien van een nofollow tag. Gebruikt een pagina meer dan één facet, geef hem dan ook een noindex tag. Daarna kunnen veelgebruikte facetten worden ‘gewhitelist’ zodat zij wel geïndexeerd kunnen worden. Met deze aanpak blijft het aantal gedupliceerde pagina’s beperkt en wordt de grootste verkwisting van het crawlbudget tegengegaan. In combinatie met canonicalization kan dit bijzonder effectief zijn, maar het vereist wel een zeer nauwkeurig ontwerp van de website. Een foutje met een tag is snel gemaakt en kan dramatische gevolgen hebben voor de zichtbaarheid van je (belangrijke) pagina’s.
Om het probleem dat ontstaat bij facetnavigatie helemaal de kop in te drukken is niet te ontkomen aan gebruik van hulpmiddelen zoals JavaScript, maar dat vereist een serieuze investering van tijd, geld en middelen en moet daarom vaak nog even op zich laten wachten. Maar tot die tijd zijn er in ieder geval genoeg mogelijkheden voorhanden om de nadelen van facetnavigatie te bedwingen en de voordelen ervan uit te buiten.
Romano leeft, eet, drinkt, slaapt en ademt zoekmachine optimalisatie. Benieuwd of jouw website technisch gezien goed in elkaar steekt? Meld je aan voor de kosteloze en geheel vrijblijvende ‘pro bono’
audit: https://seogeek.nl/gratis-seo-scan.


0 reacties